




For years, the cloud came with an unspoken agreement: spend what you need to innovate, and we'll figure out the cost later.
That agreement seems not to work anymore, is it broken?
This year, the limelight has been on Agentic AI, and it is largely driven by the high cost of new AI services. They estimate that the global cloud computing market will surpass $1 trillion by next year. That makes it a 21% year-on-year increase. Now, enterprises should realize that if they are deploying a new AI application in their workflow, it would require more emphasis on cloud cost optimization.
This surge makes it painfully clear why 7 out of 10 companies still aren't sure where their cloud budget is truly going. Do you remember the old business saying, "You can't manage what you can't measure"? I think it’s very fitting for this scenario. When costs are climbing this quickly, flying blind is not an option. That’s why we put together 17 cloud cost optimization strategies that can't be overlooked to bring clarity and control back to your cloud spending.
A good FinOps team will always recommend that scaling purely on CPU is not always efficient. A web server can be slow because of heavy network traffic or not enough memory, even if its CPU isn't busy.
Rather than simply CPU Utilization, set your autoscaling groups to utilize more meaningful metrics.
One of them is (Request Count Per Target), which typically works like Application Load Balancer (ALB) on AWS. This is one of the metrics that directly reflects the number of requests being handled by each instance. You may put a limit such as maintaining every instance with 1000 requests per minute. This optimizes your fleet considering real user traffic rather than CPU load, which is a far more useful measure of user experience and resource requirement.
In the case of worker queues, scale depends on the queue length.
In AWS, it is the (ApproximateNumberOfMessagesVisible) this is good as it measures SQS. You can establish a scaling policy that will add workers each time the queue contains more than 500 messages and remove them when it goes under 50. This will guarantee that you are not paying to compute when you do not have work to do.
This is one of the most direct ways to get more performance for your money. The Graviton (ARM) based processors of AWS. Their biggest perks are that they have a much more favorable price-to-performance ratio, sometimes up to 40 times.
Migration is not just as easy as pressing a button, but it is still pretty simple when an application is written in a language that is based on an interpreted language such as Python, Node.js, Ruby, or Java. The primary work is to recreate your application artifacts (such as Docker images) to the arm64 architecture rather than amd64. In compiled languages such as Go, C++ or Rust, you will have to re-compile your programs to run on the ARM architecture.
The starting point for this strategy is that you must run by your application on one Graviton instance (such as a m7g, c7g, or r7g in AWS). In the cases where your application and dependencies are available on ARM, the transition can be simple. The savings are significantly large, that is why this is number #2 on our list.
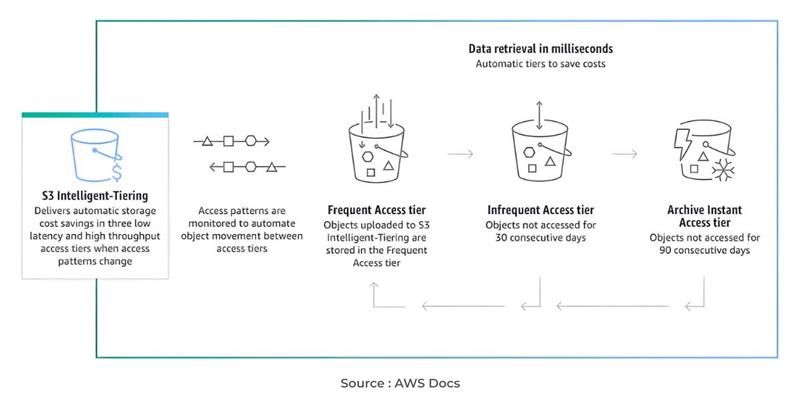
Leaving all your data in standard, hot storage tiers is like paying for a premium parking spot for a car you drive once a year. Cloud providers have automated methods to move your data to less expensive storage according to access frequency.
Amazon S3 Intelligent-Tiering is a superb tool, S3. It tracks the access patterns of your objects and automatically moves data between a frequent access tier and a far less expensive infrequent access tier. When an object in the infrequent tier is accessed, it is transferred back to the frequent tier, now it offers many classes based on your requirements. It has a small per-object monitoring fee, which in nearly all cases is cheaper than hand-managing lifecycle policies in data whose access patterns are uncertain.
This works well in user-generated content, logs, or datasets where you do not know which files will become popular and which files will be lying untouched a few months later.
Zombie resources are cloud resources that are no longer in use but remain active, resulting in unnecessary charges. How can they occur? Zombie resources can occur when cloud resources are not adequately decommissioned or deleted or when resources are left running but are no longer needed.
Examples of these include- EBS volumes that are short of attachments, idle Elastic IPs, or machine image snapshots that you continue to pay.
Don't rely on manual cleanups. Auto-detect and auto-delete. The AWS Lambda, Azure Functions, or Google Cloud Functions can be used to write simple scripts that can run weekly.
The following is an example EBS volume process:
The same reasoning can be applied to Elastic IPs (check whether it is attached to an instance) and to AMI snapshots (check whether older than a specific date and not applied to any running launch templates).
Spot Instances are idle capacity in the cloud providers, which they sell at a huge discount, sometimes nearly 90% lower than the On-Demand cost.
There is only one problem with this strategy: the provider can always reclaim them in a short time.
On Azure, it takes just 30 seconds, on AWS, it is still 2 minutes, and on GCP, it takes 24 hours.
It is much more convenient to use Spot with modern tools. AWS EC2 Fleet or Spot Fleet. They allow you to request capacity in a variety of instance types and in several Availability Zones, and this way, all your cloud instances are not affected simultaneously. You can specify your target capacity, and the service will automatically help you get the cheapest combination of Spot and On-Demand instances to meet it.
One of the well-known sources of unforeseen expenses is data transfer. In particular, the traffic going out of a VPC and back to a public service endpoint (such as S3, DynamoDB or SQS) and then back.
This process may face fees related to NAT Gateway processing and possibly data transfer costs.
VPC Endpoints address this very thing by establishing a secure, private link between your VPC and a range of AWS services. The traffic does not go outside of the AWS network backbone.
There are two types:
Use Gateway Endpoints wherever possible. In other services, calculate the price of a NAT Gateway and an Interface Endpoint. In the case of a high traffic application the endpoint is nearly always the winner.
Pre-committing to usage is a giant money saver, however, Reserved Instances (RIs) are sometimes inflexible. What should you do? AWS also provides a more flexible alternative Savings Plans.
Compute Savings Plans is the better option of most of current dynamic infrastructures. They adjust to your evolving requirements without you having to do anything. Discount is great and you are not bound to any type of instance.
Rightsizing EC2 instances is a common thing that people speak about, however, oversized RDS or other managed database instances may be even more wasteful. A database that is sitting at 90% idle CPU is only burning money.
Monitor with the tools of your cloud. Add check CloudWatch metrics to your RDS instances, namely CPUUtilization, FreeableMemory and Read/Write IOPS. When your CPU has been at 5 % utilization for one month and if you have a huge amount of freeable memory, you can safely reduce the instance.
There are also serverless databases considered with intermittent or unpredictable workloads.
AWS Aurora Serverless v2: Scales instantly from a tiny fraction of an Aurora Capacity Unit (ACU) up to hundreds. It works well with development environments, test databases, or, spiky traffic applications. You pay because you use it, when you use it.
Automated snapshots are excellent when it comes to backups, but they pile up. A daily snapshot of a 1TB volume will consume 30TB of storage after a month if left unchecked.
Implement a snapshot lifecycle policy.
The same logic applies to Amazon Machine Images (AMIs) or their equivalents. Your CI/CD pipeline may create an AMI for each build. It’s your FinOps team's job to deregister and delete AMIs of a specified age or version.
Your development, staging and QA environments do not have to be 24/7. Assuming that your group works 9 AM to 6 PM, that is 10 hours in the day. The rest 14 hours and the weekend are lost compute time. That's over 60% of the week.
Automate start/stop:
It is a low-impact, but high-impact change that can reduce your non-production environment costs by over 50%.
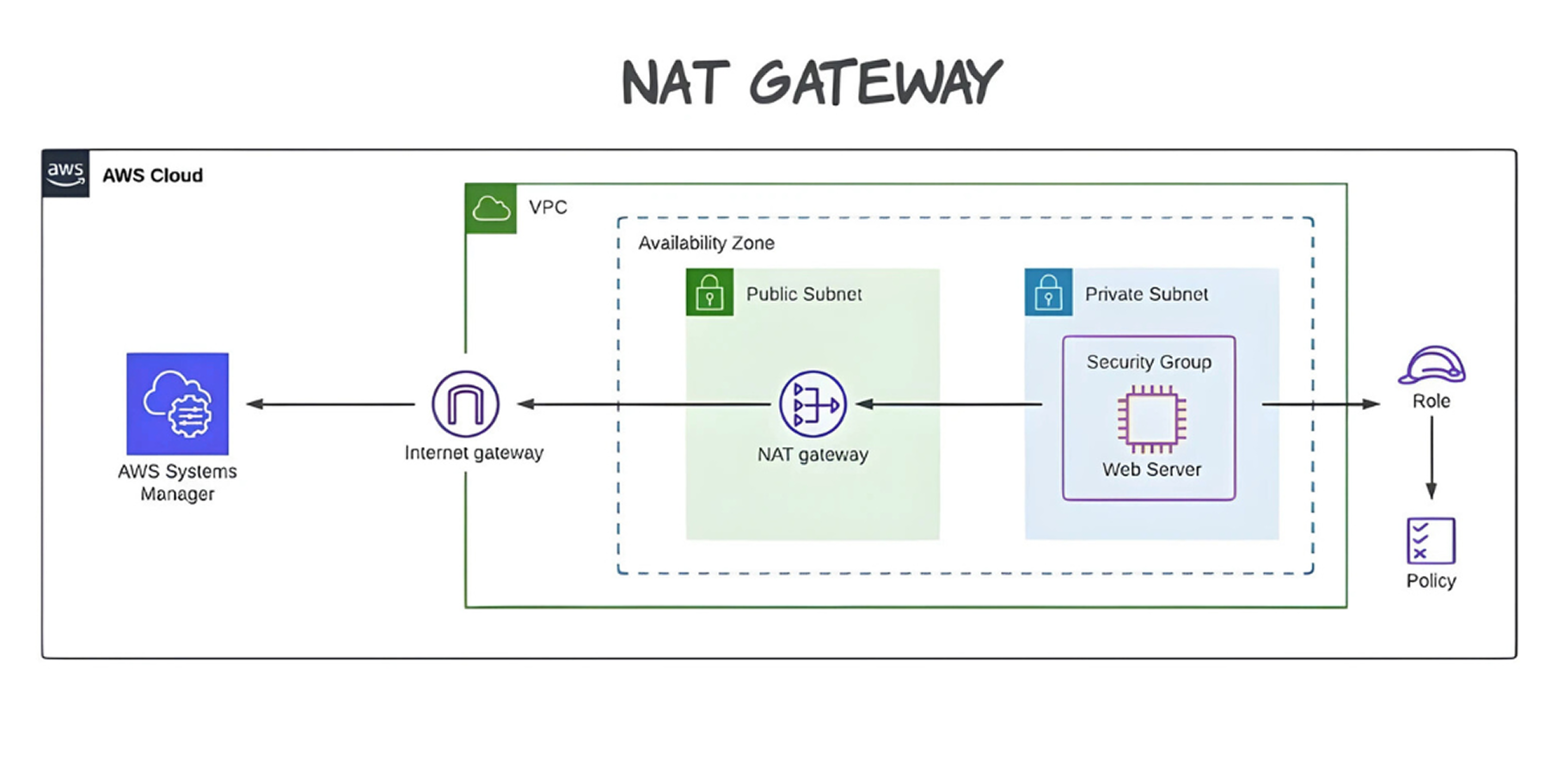
NAT Gateways are simple to install but they can become expensive. You are charged a per-hour rate on per GB of data processed. This can get pretty expensive if not optimized, not to mention that in private subnets, when you have dozens of instances making regular, small calls to the internet (e.g. to update software or make API calls), this can add up to a pretty big number.
Consider your architecture:
Every call to your primary database costs money in terms of I/O, CPU, and potentially licensing. A properly positioned caching layer can take on a vast percentage of your read traffic and enable you to run a smaller, less expensive database instance.
Managed in-memory caching services such as:
These services are low-latency optimized lookups. Caching commonly visited data, such as user profiles, product descriptions, or session data, implies your application will access the cheap high-speed cache, rather than the expensive slow database. Not only does this save money on your database, but it also drastically enhances the performance of your application.
One of the most costly forms of data transfer is data transfer out to the internet (egress). These are expensive to serve because they require you to rely on a web server or object storage bucket to serve up the content of the image, video, CSS, and JavaScript files.
This is fixed by a Content Delivery Network (CDN). It stores your content in edge locations worldwide, which are nearer to your users. When a user requests a file, it is served from the closest edge point.
You can't optimize what you can't measure. A single bill from your cloud provider is useless for optimization, it’s just not enough. You must be aware of the team, project or feature that incurs the costs.
Implement a mandatory tagging policy. Each and every resource (EC2 instance, S3 bucket, RDS database) must be tagged with important information such as:
After having these tags, then you can then use the native cost analysis tools and filter and group your spending by such tags. This enables you to visit the billing engine group and say: Your production resources cost 5,000 last month, and your development resources cost 2,000. Why is your dev spend that high? This renders cost optimization a collective burden.
For tasks that run in response to an event, like processing a file upload, handling an API call, or reacting to a database change, maintaining an idle server waiting for that event is wasteful.
This is the perfect use case for serverless functions.
Serverless is priced per millisecond of code execution. It does not cost to sit around. This is so economical where there is spiky or irregular work to be done. You do not need a 24/7 running EC2 instance to convert thumbnail images; a Lambda function can be called every time a new image is uploaded to an S3 bucket. It takes a couple of seconds and stops. Per execution, the price is frequently a fraction of a penny.
Load balancers are not free. They cost you an hourly fee to be in use, and a charge depending on the load of traffic they handle (in AWS, measured in Load Balancer Capacity Units or LBCUs).
Regularly audit your load balancers. Find those that have very few or no healthy backend targets. They may be the remains of a retired application. Even an idle classic Application Load Balancer in AWS can run more than $20 monthly.
In addition, monitor the ProcessedBytes measure. A load balancer processing only a few kilobytes of data an hour may be excessive. It may be that the application can be co-located with another behind a single load balancer by host-based or path-based routing or that the application may not require a load balancer at all.
Many enterprises already have software licenses (databases, middleware, analytics tools) under enterprise agreements. If you don’t leverage these in the cloud, you may end up paying twice, once to your vendor and once for the cloud marketplace license.
With Bring Your Own License (BYOL), you can re-use your on-premises or enterprise licenses on cloud VMs or managed services.
Avoid Double Payments: No need to pay for cloud-included licenses if you already own them. Maximize Existing Investments: Enterprise license agreements often run into millions of dollars. BYOL extends their life, improving ROI and protecting prior investments.
AWS: License Mobility with Microsoft and Oracle. Azure: Hybrid Benefit for Windows Server, SQL Server. GCP: Sole-tenant nodes with BYOL support.
Governance is often treated as an afterthought, companies often check it during quarterly reviews or compliance audits. By then, costs may already have ballooned due to oversized VMs, premium resources, or untagged deployments.
Instead, implement policy-as-code to automatically enforce cost and compliance guardrails.
Prevent Waste Before It Happens: If a resource violates policy, it never reaches production. That means wasted spend never enters your bill. Automated Alerts: Budget breaches, abandoned resources, and non-compliant deployments get flagged instantly instead of doing it a months later.
AWS: Service Control Policies (SCPs) via AWS Organizations. Azure: Azure Policy with cost-related rules. GCP: Organization Policies and Budget Alerts.
Cloud usage is dynamic — new workloads, orphaned resources, and scaling patterns appear constantly. Without regular audits, these things can silently add up to a huge monthly bill.
By reviewing resources every 90 days or less, you can catch waste before it compounds. A cost audit reviews all active resources, identifies underutilized or abandoned workloads, and validates whether resources match business requirements.
Identify Orphaned Resources: Unattached EBS volumes, idle load balancers, old snapshots, and unused IPs are often forgotten but still billable. Right-Sizing Opportunities: Catch oversized instances, storage tiers, or premium services that are no longer required. Continuous Optimization: By auditing every 90 days or less, optimization becomes proactive, not reactive.
AWS: Use Trusted Advisor and Cost Explorer to find idle resources. Azure: Azure Advisor for underutilized resources. GCP: Recommender API for VM rightsizing and idle resources.
Most Enterprises often run multiple accounts or subscriptions for business units, teams, or environments. If billing is fragmented, you lose out on aggregate usage discounts and centralized visibility.
Aggregate Usage Discounts: Cloud providers apply tiered pricing (e.g., storage, data transfer, compute). Consolidation lets you pool usage and unlock lower pricing tiers. Centralized Governance: Easier to apply policies, budgets, and alerts across the entire organization. Bulk-Buy Alternatives: If your cloud provider doesn’t credit shared usage, third-party cost platforms (like Costimizer) can provide “group-buy” models to unlock savings.
AWS: Consolidated Billing under AWS Organizations. Azure: Management Groups with consolidated billing views. GCP: Billing Accounts with linked projects.
The thing is most of the businesses pay 20-40% more than they need to, due to fragmentation in usage, complex contracts, and no one has a complete picture of what drives the bills. The snowballing on the spend starts right by the time your DevOps team can even get to the fixes, and that can cost you millions.
It is not a luxury to optimize cloud costs in 2025, but a survival strategy. All of the strategies in this article, such as scaling the right metrics down to the zombie resources and reducing hidden egress bills, are very effective. They are hard to put into practice, day to day, within AWS, Azure, or GCP.
That is where Costimizer makes the difference. We know nobody has the time to read reports; that is why we are replacing it with an Agentic Cloud Cost Optimizer- Costimizer, which responds to questions in regular language, which in turn performs fixes by itself, and which also rereads the results to ensure that nothing is lost. Whether it’s rightsizing databases and enforcing policies, or bulk tag normalization and weekend shutdowns, Costimizer is fast at work, and we have built guardrails to ensure compliance.
With Costimizer, you get clarity, savings, and peace of mind, without paying a dime unless we deliver.
The thing is most of the businesses pay 20-40% more than they need to, due to fragmentation in usage, complex contracts, and no one has a complete picture of what drives the bills. The snowballing on the spend starts right by the time your DevOps team can even get to the fixes, and that can cost you millions.
It is not a luxury to optimize cloud costs in 2025, but a survival strategy. All of the strategies in this article, such as scaling the right metrics down to the zombie resources and reducing hidden egress bills, are very effective. They are hard to put into practice, day to day, within AWS, Azure, or GCP.
That is where Costimizer makes the difference. We know nobody has the time to read reports; that is why we are replacing it with an Agentic Cloud Cost Optimizer- Costimizer, which responds to questions in regular language, which in turn performs fixes by itself, and which also rereads the results to ensure that nothing is lost. Whether it’s rightsizing databases and enforcing policies, or bulk tag normalization and weekend shutdowns, Costimizer is fast at work, and we have built guardrails to ensure compliance.
Here’s what we do:
With Costimizer, you get clarity, savings, and peace of mind, without paying a dime unless we deliver.
We use autonomous agents to find and fix waste in your AWS account. They automatically downsize idle EC2 instances, delete unattached EBS volumes, and identify savings on RDS. You set the rules; the AI executes the cleanup 24/7.
We give you one dashboard to see all your spending across AWS, Azure, and GCP. More importantly, you create one set of cost and tagging policies, and our agents enforce them everywhere. You get complete control with our multi-cloud cost management instead of trying to manage three separate systems.
We break down the costs inside your clusters to show you which namespace, deployment, or pod is spending your money. Our AI agent then finds overprovisioned containers and recommends precise resource adjustments. This is how real Kubernetes cost optimization is done, stopping waste without affecting performance.
We believe FinOps best practices should be automated, not managed in spreadsheets. Our platform automates cost allocation with tagging, enforces budgets with AI agents, and provides engineers with direct feedback on their spending.
AI-driven cloud optimization assists you by giving you reports and insights related to your cloud cost. What we do is different. We do Agentic AI that doesn't just create reports for you to read. You provide our autonomous agents with a set of rules and permissions, and they actively work to reduce your bill by resizing, scheduling, and deleting unnecessary resources. It's about active management, and it’s all in your control.Shape
Our AI Agent continuously analyzes CPU, memory, and storage metrics across your RDS, Aurora, SQL Server, and other managed DBs. When it detects long-term underutilization, it flags the exact instance type you can downgrade to—removing guesswork and saving money safely.
Both. Costimizer specializes in identifying inefficient queries consuming unnecessary resources and also recommends the right instance size. Instead of manually digging through logs, you get AI-driven query insights and automated rightsizing suggestions in one dashboard.
We tag underutilized resources, predict workload impact, and recommend downsizing paths. Our AI agent locates unused RDS, EC2, and snapshots and schedules termination after checks confirm there’s no risk to running services, this process is completed all within policy guardrails.
Our AI agent evaluates your historical usage and workload stability to recommend the exact mix of Savings Plans, Reserved Instances, or On-Demand. It also alerts you when you’re overcommitted, preventing lock-in to wasteful capacity.
Costimizer detects excessive I/O requests or unused replicas and suggests cheaper storage classes, caching, or right-tiering Aurora instances. AI-driven alerts highlight when memory upgrades or replicas would cost less than sustained I/O spikes.
Our AI ranks opportunities by impact vs. risk. You see a prioritized roadmap: “quick wins” (like idle cleanup) first, followed by medium-risk optimizations (like downsizing), and finally long-term savings (like re-architecting workloads).
With Costimizer, yes. Our lightweight AI agents integrate directly with CloudWatch, Azure Monitor, and GCP metrics. Even small teams without a FinOps practice can automate rightsizing decisions, avoiding manual spreadsheets and guesswork.
Our AI compares the licensing, compute, and storage costs of SQL Server vs. PostgreSQL/MySQL for your exact workload. It even simulates potential savings so you can confidently decide whether a migration is worth the effort.
Native tools give point-in-time hints. Our AI goes further by combining multi-cloud data, historical trends, and real-time anomaly detection. This provides context-aware, actionable recommendations, which is something native tools won’t be able to achieve in isolation.
Our AI agents continuously scan for idle databases, orphaned storage, old snapshots, and zombie clusters. Instead of just flagging them, Costimizer lets you enforce cleanup policies automatically. These are backed by retention rules to avoid accidental data loss.
Table of Contents
Explore our Topics
Having delivered value from Day 1, customers have literally texted us that we could charge them, but Costimizer continues to be a free product for our customers








