




We know AWS gives the user 200+ services, but it also gives them an endless bill. This article tells you how to stop those bills.
For many organizations, the monthly AWS bill has become one of the largest and most unpredictable items in their master budget. It’s not like the organizations have a spending problem; it’s mainly the visibility problem.
In 2025, almost every company is part of the Gen AI race, and they are trying to stay ahead, launching faster, building smarter, and scaling bigger. But in the urgency to compete, many overlook their AWS costs. With 82% of enterprises already overshooting their cloud budgets, competing hard without cost control doesn’t make sense anymore, it’s unsustainable.
As Werner Vogels, CTO of Amazon, famously said, "Costs will spiral, all the time... unless you are actively managing them."
Over the last couple of months, We have looked at more than 40 different AWS cost audits. A few common threads appeared again and again. Organizations aren't lazy or careless; they're just falling into some very common traps that are easy to overlook when you're busy building things. Let’s get straight into it!
Choosing the right pricing model can be tough, it can also be the one lever which would reduce your AWS bill. One of the common mistakes is to leave the majority of workloads on the default On-Demand is the pay-as-you-go model. You only pay per second on compute capacity, and no long-term contracts or advance payments.
On- Demand model, which also happens to be the most expensive. A good thought-out strategy would involve layering different models to match your own workloads and its design.
When to Use It:
The Mistake You Have to Avoid: Complacency. On-Demand is the simplest AWS tool, and that is why companies use it as a default for everything. Any workload that continuously runs over months on-Demand will not give you the best saving opportunities.
Savings Plans (SPs) are a price structure that achieves high savings in return for a commitment to a fixed level of compute usage (measured in $/hour) over 1 or 3 years. They have become the usual preferred choice for most users.
Before Savings Plans, Reserved Instances were the primary way to get a discount. They still exist and can be useful in specific scenarios.
Spot Instances let you use spare AWS compute capacity for up to 90% off the On-Demand price. The catch is that AWS can reclaim this capacity with a two-minute warning.
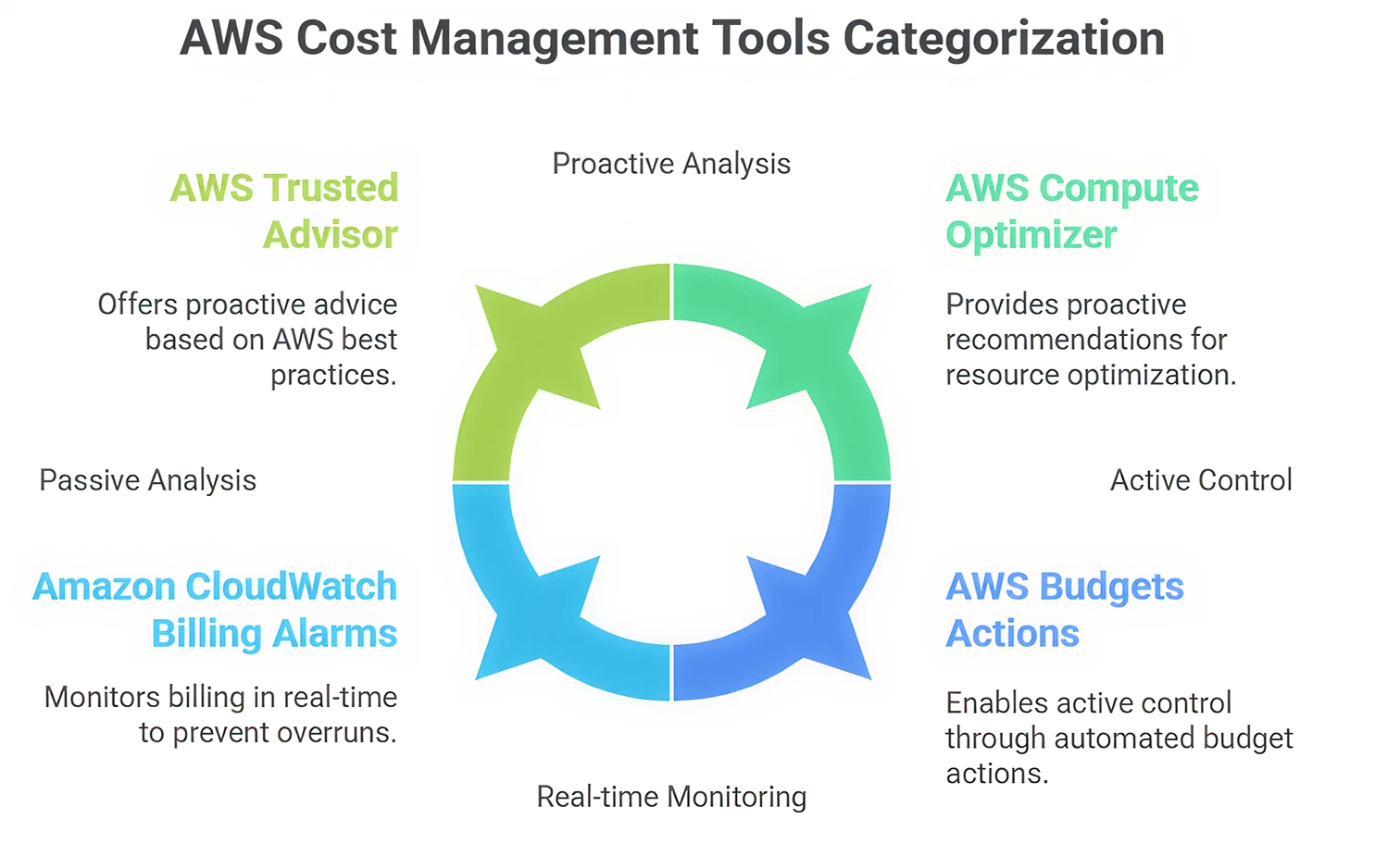
AWS provides a powerful suite of native tools to help you analyze, control, and optimize your costs. Mastering them is non-negotiable. We have divided them into
This is your primary interface for analyzing your spending.
Deep Analysis: Go beyond the default view. Use the grouping and filtering features to break down costs by linked account, region, service, and, most importantly, cost allocation tags. Create saved reports for your key projects to review them quickly each month.
Projections: The in-built forecasting can be used to project your monthly expenditure. One of the downsides is that it hasn't been updated recently and may not be very useful at predicting sudden spikes due to new projects.
This takes you off the passive analysis onto the active control.
StartFragment
This is a free machine learning-based tool that can analyze the use of your resources and offer right-sizing recommendations.
It is a kind of automated consultant, which gives real time advice according to AWS best practices. Although it includes checks on security and performance, its cost optimization checks are priceless.
Key Cost Checks:
Amazon CloudWatch Billing Alarms:
As detailed in the AWS documentation, this is your first priority against budget overruns. It allows you to monitor your estimated charges and get notified when they cross a threshold you define.
Step-by-Step Setup:
The best practices we’re about to discuss are quick wins. If your environment isn't gigantic, you could get most of this done within a week.
The first step is a full review of every resource in your AWS account, from production to dev environments. Look at their utilization over the last month. You can use AWS CloudWatch or your own monitoring tools to get the data you need. Group everything into three buckets:
Once you've sorted your primary resources, it's time to look at your data. Data costs can pile up in unexpected places, particularly with snapshots and storage.
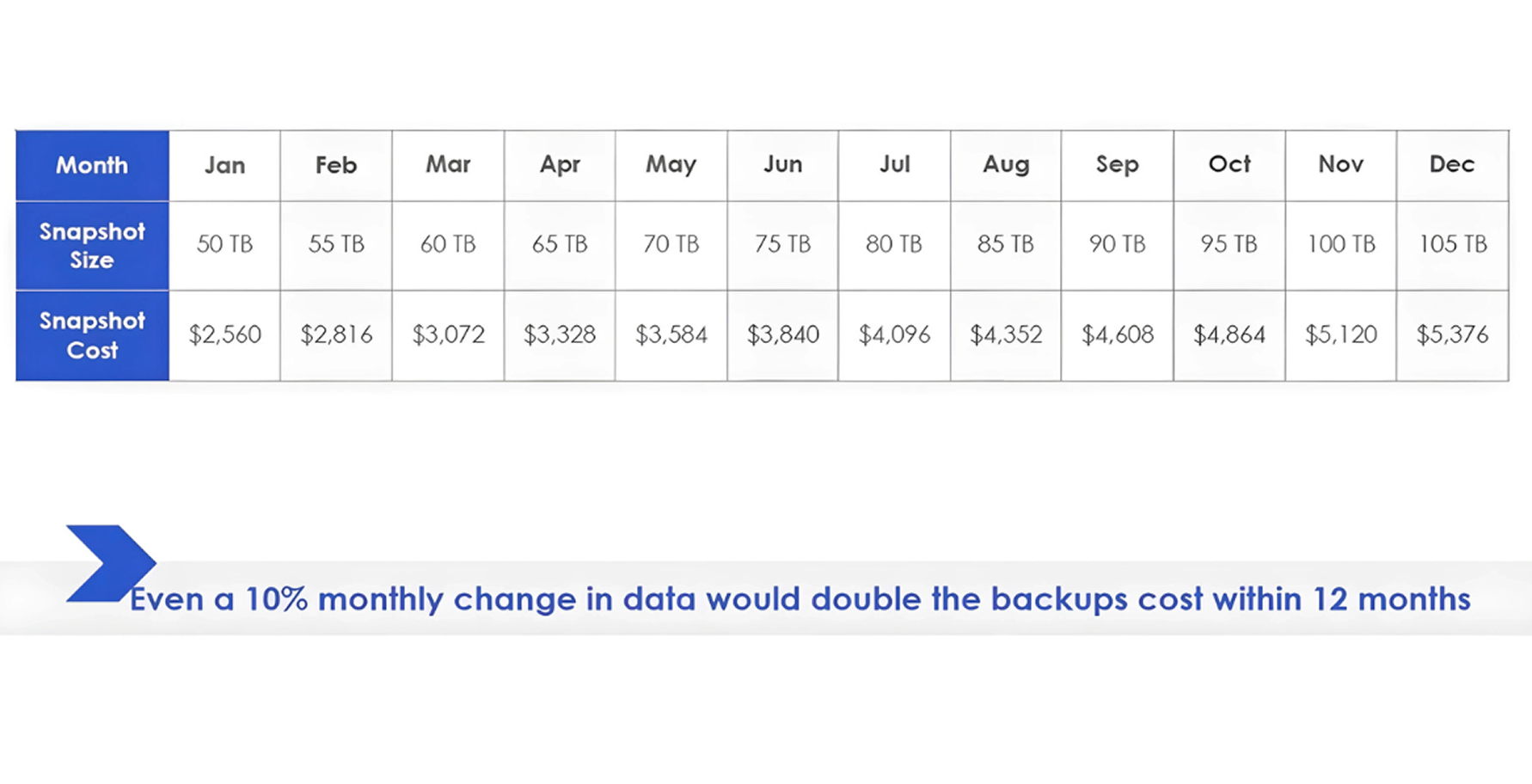
Snapshot charges get out of control very easily. They are also used as a backup by people, commonly using home-written automation scripts. The issue here is that the script which generates the backups runs to completion flawlessly, and the one which deletes old-dirty ones does not run at all. Most of the SMEs see the monthly snapshot fees have become more significant than the cost of the underlying EC2 instances to which they were making a backup.
Let’s take one hypothetical example, a bill would begin at zero and increase more than $5,000 in one month of snapshots alone.
The key takeaway here is to offload this operational burden.
To do this automatically, AWS Backup or Amazon Data Lifecycle Manager is used. These are services designed to handle all the lifecycle of your backups, such as deletion. And just come and check your snapshot charges immediately.
The majority of them fail to differentiate between the S3 Standard storage class and use it everywhere. This is the most costly alternative. There are 2 major factors on which S3 storage is charged: storage amount and retrieval frequency.
This is a basic example: the storage of 50 terabytes of information.
When you are backing up data that you will only access once or twice a month, then you have to back up using S3 Standard-Infrequent Access (Standard-IA). One Zone-IA can be used when you have temporary data to use. For long-term archival,
S3 Glacier or Glacier Deep Archive are extremely inexpensive, however, they offer varying SLAs regarding both retrieval time and durability. You should have a good cost analysis before you move anything based on your pattern of retrieval.
One of the most complicated elements of an AWS bill is data transfer. Prices are determined by the origin, destination and the amount of traffic.
First, a basic validation: when you have workloads in the same Availability Zone communicating using private IP addresses there is no cost. When they are using public or elastic IPs to communicate, you are paying. Go back and ensure that your applications are using IPs that are private when communicating between them.
Second, turn compression everywhere. Turn it on your CloudFront distributions, on your web servers, and when you upload data to S3. We have discovered that CloudFront will normally disable compression on default, and enabling it can save you a lot of money in data transfer.
Third, when traffic across your private subnets and other services, such as S3 or DynamoDB, is large, the traffic is typically routed over a NAT Gateway, which you pay. You can use
VPC Gateway Endpoints to send this traffic over the AWS private network instead. This can help save you a substantial amount on your NAT Gateway and data transfer bill.
It is time to stop correcting the mistakes that happened in the past and create a more intelligent and proactive system.
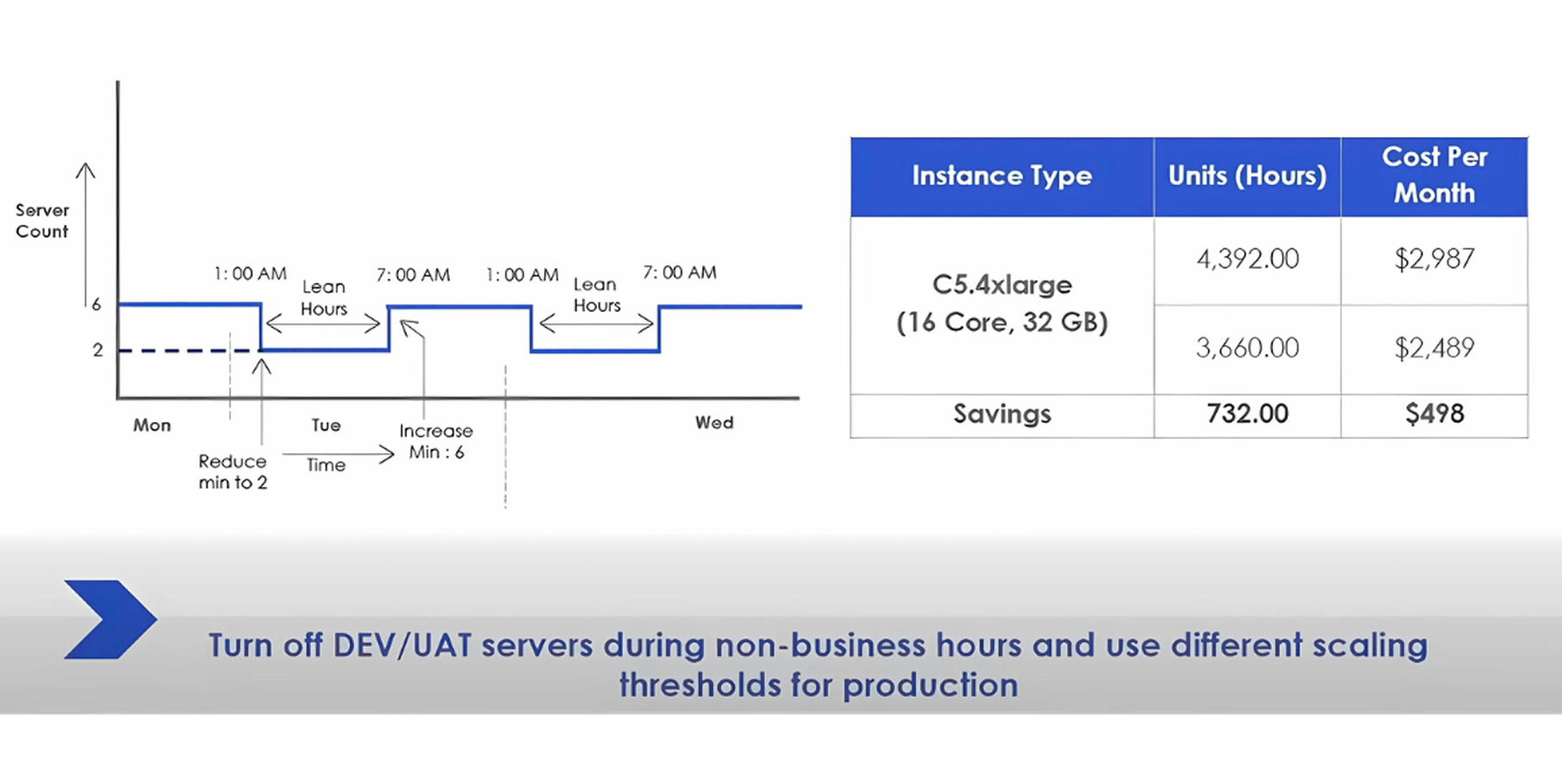
The majority of a business does not have a steady flow of traffic 24/7. When examining an e-commerce site, the number of visits could drop off a cliff after midnight and re-establish itself around 9 a.m. However, there are numerous individuals who operate as many servers as possible on a 24-hour basis.
As an example, imagine a customer with half a dozen c5.4xlarge instances running for one month, at prices of almost $3,000. They would be saving more than half a yearly monthly by just reducing the number of servers by half, down to two, during the lean periods. This is the easiest trick that carries a big effect.
You can do the same to all of your non-production environments-dev, UAT, staging. Switch them off during the weekends and holidays. This alone can save you 20-25%. This is true of EC2, RDS and currently even Redshift clusters can be put on hold.
And this is where the largest savings are lurking.
Spot Instances can reduce EC2 prices by 90%. The official AWS documentation may sound threatening, as there are warnings of interruptions. In practice, however, in the majority of workloads the interruption rate is not more than 5%.
On average, 1 in every 100 companies experiences a host interruption each month. Any workload that is running on an Auto Scaling group qualifies as a good candidate for Spot. It can be nothing but a change of configuration. Test your non-production environments first to get used to it, and then in production.
The other game-changer is serverless architecture. When you deploy services such as Lambda and S3 to a static site, you no longer pay to have idle capacity. Consider that you are doing a marketing microsite as part of a campaign. You don't know whether you will have a thousand or a million visitors. Previously users over-provision servers on a just in case basis. The serverless approach is to design it in such a way that it can infinitely scale and you only pay as you use it. It removes the hassle of dealing with servers and is cost effective.
The quick wins are awesome, but when you want to be cost effective in the long run, you have to implement some larger and more strategic changes.
All AWS regions do not cost the same. North Virginia (us-east-1) is widely the least expensive region, not only of servers, but of data transfer, storage and most other services. By way of comparison, the Mumbai area can be as much as 40 percent higher. Although your data residency or latency needs may be stricter than you need, at least some of your non-production and internal-facing applications should be hosted in North Virginia.
Also, look at your processors. Amazon provides examples of AMD processors as well as Intel. m5 (Intel) and m5a (AMD) will have the same vCPU and RAM, but the AMD one is cheaper. AMD is approximately 10 percent lower in North Virginia. It is a huge 35% less expensive in Mumbai. You save a lot of money with just a few flicks, if your application does not demand Intel.
RIs are mostly no longer used.
Savings Plans provide the same degree of discounts but are much more flexible and less of a hassle to manage. They automatically extend to the best-fit instance types and can even extend to Fargate and Lambda usage.
One note of caution- the default RI utilization reports in the AWS Cost Explorer are deceptive. They tend to be latent and are not cost-based, but rather number based. An even more effective way is to keep a record of your coverage: what fraction of your bill is paid with Savings Plans compared to what you pay per-demand? Track this by creating custom reports.
Once you've cleaned up your environment, how do you keep it that way? You need to build cost awareness into your company's DNA. This comes down to two things: tagging and reporting.
Tagging is a powerful tool for accountability. You should have a strict tagging policy for all resources, with tags for business unit, application, environment, and owner. Use these tags to generate reports and charge back the costs to the teams that are actually using the resources. No costs should be allocated to a generic "central IT" bucket. This forces every team to take ownership of their spending.
Reporting needs to be real-time and accessible to everyone. Every application owner should be able to see their costs from yesterday and today and understand what caused any changes. Push this information out through email or Slack. Create simple dashboards showing the top 10 cost-incurring resources of each type (EC2, S3, RDS, etc.). When the information is readily available, people will find the time to act on it.
Cost management needs to be a discipline, just like testing or agile development. It shouldn't be a periodic emergency drill you run once a quarter. When it becomes an ongoing practice for everyone, you'll find you don't have to "cut" costs anymore.
The truth is simple AWS isn’t “expensive.” Unoptimized AWS usage is expensive. And that’s why cost optimization is no longer optional; it’s a core competency for every business scaling on AWS.
This is where https://costimizer.ai/ becomes a differentiator. Unlike AWS native tools that simply show you “what you spent,” Costimizer is an Agentic AI, which analyzes usage patterns, predicts spend trajectories, and recommends precise actions to reduce costs without compromising performance & compliance.
Here’s what you get with Costimizer:
The Results You Can Expect with Us
How much does it cost?
We don’t charge you anything extra, we only ask for a small percentage of what we save for you. We know every dollar wasted on AWS is a dollar not invested in growth. With Costimizer, you’re not paying for another dashboard, you’re paying for intelligent AI models trained on your own data enabling clarity, control, and continuous savings.
With Costimizer, You don’t just react to AWS Bills, You gain complete control.
You can't just tell them; you have to show them. Frame it as a performance-tuning exercise, not just a cost-cutting one. Use AWS Compute Optimizer data to highlight instances that are massively over-provisioned (e.g., running at 5% CPU). Propose a collaborative "Optimization Sprint" where you test the top 5 most wasteful instances together. By making them part of the solution and guaranteeing a safe testing process, you turn an adversarial task into a shared goal.
This is a common fear. Don't think of it as an all-or-nothing decision. Start small and be conservative. Analyze your last 3-6 months of usage and identify the absolute lowest, rock-solid amount of hourly compute spend you've ever had. Cover just that small, guaranteed amount with a 1-year, no-upfront Compute Savings Plan. As you grow and your baseline usage becomes more predictable, you can purchase additional, incremental plans.
After EC2, the most common culprits are:
Data Transfer: This is often the #1 hidden cost. Look for traffic between Availability Zones or out to the internet. Aggressively use a CDN (CloudFront) and VPC Endpoints.
NAT Gateways: A single NAT Gateway can cost over $30/month plus data processing fees. If you have many of them, this adds up fast.
Idle Resources: Check for unattached EBS volumes, idle Elastic Load Balancers (~$20/month each), and unassociated Elastic IPs.
Logging: Excessive, high-resolution custom CloudWatch metrics or large volumes of VPC Flow Logs can become surprisingly expensive.
Don't try to master everything at once. Focus on the 80/20 rule:
Hour 1: Visibility. Set up a CloudWatch Billing Alarm for your total monthly budget. This is your safety net. Then, spend time in Cost Explorer to find your single biggest service cost.
Hour 2: Action. Go to AWS Compute Optimizer. Look at the recommendations for that one top-spending service and identify the single most over-provisioned resource. Your entire week's goal is to create a plan to safely right-size that one thing. Start small, build momentum.
The key is to frame the data as a tool for empowerment, not punishment. Never present costs without context. Instead of a report that says "Team A spent $5,000," create a dashboard that shows "Team A's new feature served 100,000 users for a cost-per-user of $0.05." Celebrate teams that reduce their cost-per-transaction as efficiency heroes. This turns cost management into an engineering challenge, not a financial penalty.
Generally, no. Three years is a very long time in the tech world. New, more efficient instance types will be released, and your own needs will change. A situation like the recent pandemic showed that business needs can change dramatically, and you don't want to be locked into paying for capacity you aren't using. Sticking to one-year Savings Plans offers a good balance of discount and flexibility.
It varies, but a healthy split is typically around 20-25% for non-production and 75-80% for production. If you're spending significantly more than 25% on your non-production environments, it’s a strong sign that you have idle resources or are not scheduling shutdowns during off-hours.
They help with visibility, and yes they are helpful but to give them a classification their tool is mainly reactive. Whereas Costimizer is more proactive, it gives you solutions within guardrails.
Table of Contents
Explore our Topics
Having delivered value from Day 1, customers have literally texted us that we could charge them, but Costimizer continues to be a free product for our customers








